|
|
Библиотека Интернет Индустрии I2R.ru |
||
Сыскное агентство WindowsСегодня невозможно представить себе "виртуальную" жизнь без поисковых машин. В Internet действительно есть все, но попробуй отыщи. Однако, привычно копируя с таким трудом найденные материалы на жесткий диск своего ПК, мы и его постепенно превращаем в свалку документов. Как же не утонуть в этом море информации? Насколько эта тема актуальна? Естественно, каждому -- свое. Все зависит от назначения и характера использования ПК. Если он -- всего лишь дорогая игрушка, то вряд ли описанные в данной статье проблемы озаботят пользователя. Если же ведется хоть какая-то "реальная" работа, то рано или поздно накопится изрядная библиотека: справочная информация, всевозможная документация, собственные "шедевры". У меня, к примеру, она относительно невелика -- около 1000 файлов суммарным объемом в 100 MB (PDF, DOC, реже -- в других форматах). Однако рубрикация (раскладывание по папкам) уже не слишком помогает. Без применения специальных средств и методик поиск нужного материала может отнять несколько минут и так и не увенчаться успехом (особенно с учетом того, что многие популярные форматы -- бинарные, т. е. обычный текст в них не "виден"). Именно необходимость организации универсального хранилища документов, обеспечивающего максимально мощный и удобный механизм поиска информации, является, в частности, и одним из важнейших стимулов к разработке новых файловых систем. К примеру, Microsoft для этих целей собирается использовать (в будущих версиях Windows) SQL-механизм баз данных. Почти три года назад мы уже публиковали обзор локальных поисковиков, и тот факт, что все они (как проекты) сохранились и доныне, косвенно свидетельствует об актуальности выбранной темы. Однако ситуация на рынке с тех пор существенно изменилась, и в настоящее время таким программным продуктам приходится соперничать не только между собой, но и с ПО самой Microsoft. Indexing Service Действительно, все пользователи Windows 2000 и Windows XP (а раз так, то и всех последующих версий, поскольку линия 9x прервалась окончательно) автоматически получают в свое распоряжение довольно мощное поисковое средство -- Indexing Service. Появившись еще во времена Windows NT 4 под именем Index Server (распространялся в составе Option Pack), продукт превратился в стандартный компонент Windows 2000. Он по умолчанию устанавливается в систему, однако остается неактивным, и его даже можно преспокойно удалить через Control Panel, что и рекомендуют сделать многие онлайновые руководства по оптимизации Windows.
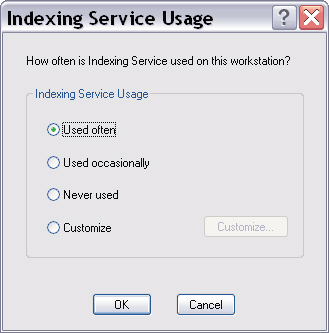
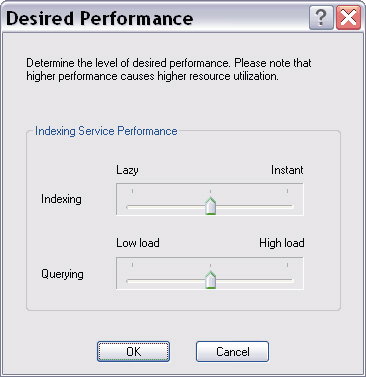
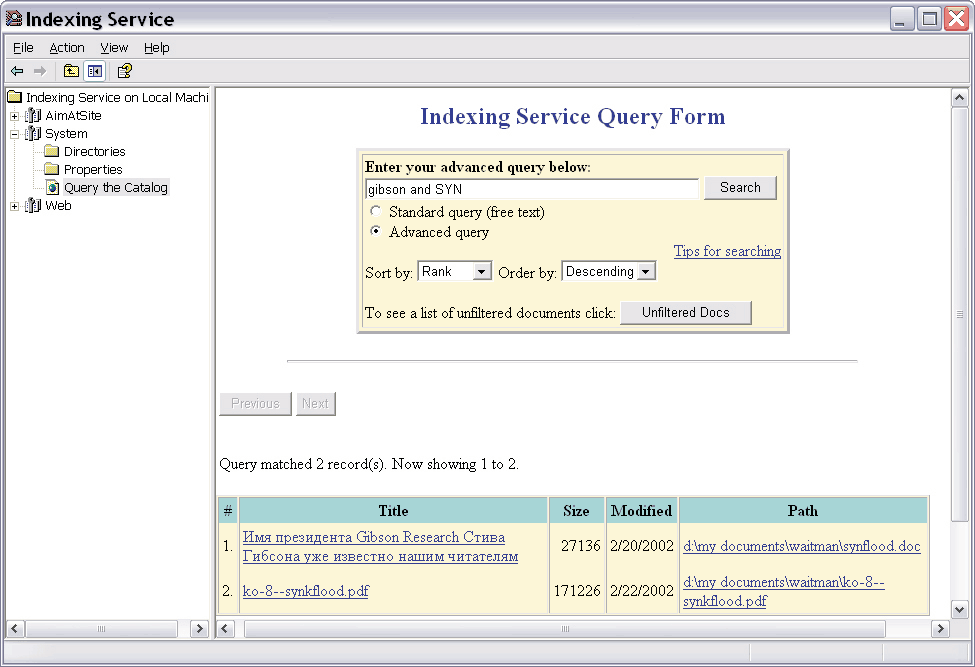
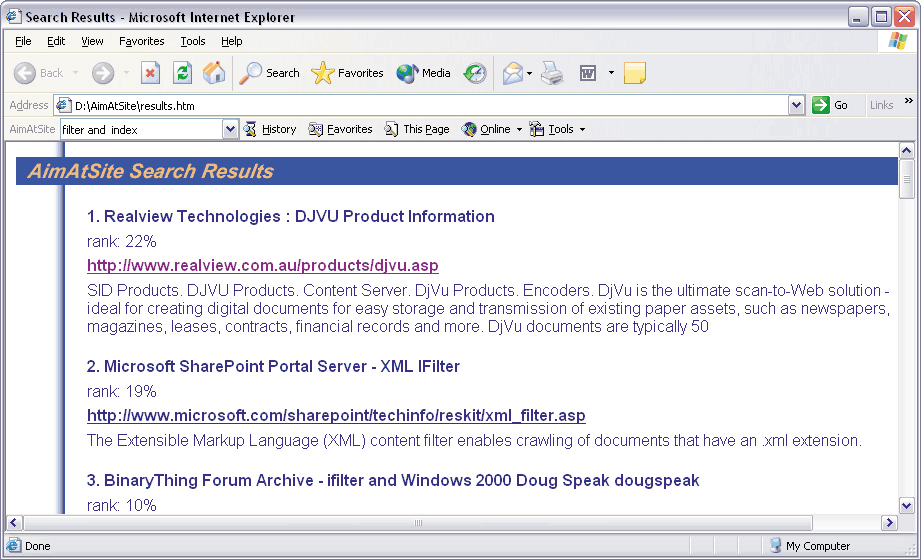
В отличие от большинства аналогичных продуктов создание индекса для Indexing Service не является "отдельной" операцией. Вы можете инициировать этот процесс, но в дальнейшем служба будет работать по своему усмотрению, в частности начнет максимально задействовать моменты простоя системы и откладывать "на потом" ресурсоемкие, но некритичные операции вроде оптимизации индексных файлов. Изменения в обслуживаемых папках отслеживаются фактически в реальном времени (особенно на NTFS), поэтому необходимость планирования операций обновления индекса, характерная для сторонних продуктов, отсутствует как таковая. Впрочем, в этом есть как положительные, так и отрицательные моменты: с одной стороны, фоновый режим функционирования службы делает ее практически незаметной, с другой -- нельзя быть уверенным в актуальности индекса, особенно на начальной стадии. Службой Indexing Service можно довольно гибко управлять. Соответствующий апплет находится в Control Panel -> Administrative Tools -> Computer Management. Однако для более подробного знакомства и изучения гораздо удобнее вынести на Рабочий стол ярлык для ciadv.msc из \WINDOWS\ system32, а заодно -- и для is.chm из \WINDOWS\Help. В основе функционирования Indexing Service лежит понятие каталога, представляющего собой совокупность реальных папок, для которых операцию индексирования можно разрешать или, наоборот, запрещать. Прямой смысл -- максимально ограничить поисковую зону. Если все полезные данные вынесены на отдельный диск, его стоит указать "целиком", а затем исключить лишние папки. Это позволит оперативнее строить запросы. Чтобы изменения вступили в силу, службу необходимо остановить и запустить вновь. Кроме того, можно принудительно инициировать операцию повторной индексации -- полную или инкрементную. Для каждого каталога имеется также особая форма для построения запросов, которые будут гарантированно обрабатываться через индекс (при использовании стандартного поискового средства Windows все будет зависеть от выбранной зоны поиска). Еще одна полезная возможность этого апплета -- слежение в реальном времени за функционированием службы: количеством обработанных документов, размером индексов и пр. Но, пожалуй, интереснее всего то, как Indexing Service добывает из файлов полезную информацию. Для этого используются так называемые фильтры. Microsoft предоставляет только относительно небольшой их набор -- для текстовых файлов (в том числе и с различной разметкой, например HTML) и документов Microsoft Office (сам пакет при этом не нужен). Фильтры не только извлекают из соответствующих файлов весь текст, но и выделяют так называемые "свойства" (или метаданные) -- имя автора, название, ключевые слова, содержимое и т. д. Естественно, магии здесь никакой нет -- все атрибуты должны заполняться автором документа (при условии, что формат поддерживает эту возможность). Для поиска по свойствам приходится применять формальный язык запросов, который, впрочем, пригодится и в других ситуациях. Например, с помощью
или
(соответственно, короткая и полная форма) можно найти все документы, полное имя автора которых начинается с Igor. Поддерживаются логические операции и регулярные выражения, однако тема эта довольно обширная, так что лучше обратиться к документации и справочной системе.
Упомянутые фильтры представляют собой подключаемые модули, а в составе Microsoft
Platform SDK распространяются необходимые инструменты и документация для их разработки.
Соответственно, другие компании могут достаточно просто реализовать поддержку
своих собственных форматов, чем некоторые и не преминули воспользоваться.
Существуют и более экзотические фильтры: для чертежей AutoCAD, для MP3-файлов, для документов WordPerfect
от Corel. Сама Microsoft дополнительно разрабатывает фильтр для XML, основная ценность которого
заключается в поддержке метаданных (без этого поиск в XML-документах осуществляется
как в обычных текстовых файлах). А Document Imaging из состава Microsoft Office
XP позволяет индексировать сканированные TIF-страницы, "на лету" выполняя распознавание. |
|
| 2000-2008 г. Все авторские права соблюдены. |